 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetThe House of Lords and Supercomputing
About one year ago, in April 2012, the House of Lords invited the International Supercomputing Conference ISC’13 General Chair Hans Meuer to deliver a presentation with a rather provocative title: Supercomputers – Prestige Objects or Crucial Tools in Science and Industry.
Dr. Meuer, a professor of Computer Science at the University of Mannheim and general manager of Prometeus GmbH, co-authored the paper with Dr. Horst Gietl, an executive consultant at Prometeus.

Figure (L-to-R): Professor Hans Meuer, Lord Laird and Kevin Cahill
Why would the venerable House of Lords be interested in supercomputing? For one thing, the Second Lorraine King Memorial Lecture was hosted by Professor John Dunn Laird, the Lord Laird of Artigarvan, a former computer programmer.
A professional computer expert is now part of the House of Lords, as perhaps a recognition of the roles Computer Science and IT play in our society and in the production of wealth. This is the House of Lords of the 21st century.

It is also noteworthy the House of Lords invited a worldwide expert, Dr. Meuer, who is not British, but German. In the absence of a Nobel Prize for computer science, the Lorraine King Memorial Lecture may become (why not?) one of the more prestigious events to honor great men and women advancing the computer industry.
Dr. Meuer told his audience about the TOP500 supercomputer project, which was launched at the University of Mannheim, Germany, in 1993. It is the only project in the world that has been successfully tracking and evaluating the supercomputer market for 20 years. Two TOP500 lists are published per year, one at the International Supercomputing Conference in Germany in June and one at the US-based Supercomputing Conference (SC) in November.
 |
|
Professor the Lord Laird of Artigarvan |
The distinguished audience learned that the UK ranked 4th in the TOP500 list of supercomputer-using countries and that France was the only European country with any capability to manufacture supercomputers. With true British humor, the Lords reaction is fittingly described by one blogger reporting the event:
Clearly more needs to be done by the likes of the UK or Germany to remain competitive in the Supercomputing stakes, which begged the question, (as posed later by an attendee), of whether these machines were nothing more than objects of geopolitical prestige, superiority and / or bragging rights, (e.g. My Supercomputer is faster than yours, so Nyah-nyah, nyah-nyah nyah-nyah!)
Lord Laird summarized this by saying that the supercomputer industry has “a certain lack of visibility,” adding ”if we don’t know who you are, or what it is you want, then that is entirely your own fault!“
Next >> Soccer and Supercomputing
Soccer and Supercomputing
In hindsight, the words of Lord Laird suggest an appreciation for entrepreneurial spirit and for the great effort that has gone into bringing supercomputing to the world’s attention against skepticism and ironic smiles. Hans Meuer is a chess player and, like me, a soccer aficionado. In my recent conversation with him and Horst Gietl, Dr. Meuer asked me the first question:
Hans: Do you know what my favorite soccer team is?
I watch soccer on GolHD and Fox Soccer TV channels in California.
Miha: Bayern? Dortmund?
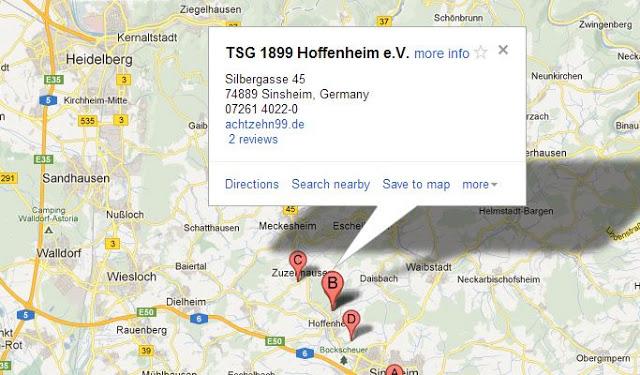
Hans: TSG Hoffenheim
Miha: Hoffen… what? Are they in Bundesliga 1?
 |
|
TSG Hoffenheimer “in the middle of nowhere” 🙂 |
Hans: Hoffenheim is a small village of 3,000 people about 15 miles south of Heidelberg. As you say in America, it is in the middle of nowhere. When I came here in 1974, the team played the lowest possible league in Germany, called Kreisliga, about seven levels below Bundesliga 1. Dietmar Hopp, one of co-founders of SAP, spent his childhood in Hoffenheim and played soccer. He invested in the team and in 2008 we entered Bundesliga 1.
[Note that Dietmar Hopp is on the Forbes list. He is the 185th richest individual in the world with a net worth of $6.5 billion.]
TOP500 Beginnings
Miha: After 20 years, the TOP500 list you helped create became a prestigious membership coveted by every supercomputer team, manufacturer and country anywhere in the world. How did it all start?
Hans: Erich Strohmaier and I came with the TOP500 idea at Mannheim University at the beginning of 1993. Later, we knew we needed US to buy the concept. I asked Jack Dongarra (father of Linpack) to become one of the authors from the very beginning; Horst Simon became an official author in the year 2000. We are four TOP500 authors: Meuer, Strohmaier, Dongarra, Simon.

|
Erich Strohmaier describes the TOP500 experience elsewhere: “When we started this, it was to gather statistics for a small conference. We never expected the scope and popularity to grow as it did.” It took two or three years for the list to find its footing. Initially, a number of manufacturers were reluctant to provide the necessary data….only those who were sure they would have a good showing submitted their data to us…Some companies don’t want to be listed because they see their systems as giving them a competitive advantage and don’t want their competitors to know either the size or type of their machines… some centers are conducting classified research and say, ‘Thou shall not publish our system.’ Some institutions are reluctant to devote their entire supercomputer to running the Linpack benchmark. Linpack, they said does not represent a real workload and therefore skews the performance levels. “That’s all in the spirit of the game – we have a number of big players, but also many of the smaller players are very proud, and that shows how important HPC has become to the research community.” |
To get to where it is today, the TOP500 ran the same roller coaster as the TSG Hoffenheim soccer team. Hans Meuer and his partners created the TOP500 ex nihilo many years before Lord Laird’s witticism: “If we don’t know who you are, or what it is you want, then that is entirely your own fault!”
Regarding Linpack, sure the benchmark has limitations. It scales very well, but it is not a guide to select a supercomputer, per se. The ideal supercomputer for you is the one that runs the applications you are going to use best, within the maximum budget you have. And in terms of performance, a ranking of 450 can be much better for you than a ranking of 400.
The main virtue of Linpack is its proven ability to forecast the future of HPC performance as illustrated in the figure below.
 |
|
The well known graph of Moore’s Law for Supercomputers |
Miha: How would you explain its success today to group of young people?
Hans: The success of the TOP500 is based on the fact that it is the only tool available for evaluating the HPC market in 20 years and that we have introduced from the very beginning as a competition on different levels: between manufacturers, between countries, and between sites. People like competitions because they like sports.

ISC’13 will also host the second HPCAC-ISC Student Cluster Challenge, one of the most popular young people event aspiring to become HPC gurus. In April 2013, the Asia Student Cluster Challenge (ASCC) will hold a competition to decide the two teams who will travel to Leipzig, joining teams from the US, Scotland, South Africa, Germany, and Costa Rica.
The Ant Algorithms, non-centric HPC, Big Data, and Bosco
Miha: IDC predicted in 2010 that in 2013 “most of the biggest, baddest supercomputers are architectural clusters or x86 MPPs with bulked-up interconnects and support for MPI or PGAS languages.” IDC calls this “evolutionary change.” What about some revolutionary change?
Hans: If the revolutionary change means the availability of GPGPUs, then we already have the revolution. I doubt that there will be any manufacturer producing chips only for use in HPC-systems. The market is not big enough. But there will be developments like Intel’s MIC multiprocessors or further developments for GPGPUs, not to forget IBM and Fujitsu, that will drive the HPC performance increases, but in an evolutionary way.
Miha: You often said multicore processors will be significant in HPC. In what way?
Hans: Multicore processors are the basis of all HPC-systems worldwide. This will not change in the near future because currently it’s the only way to speed up system performance. Therefore, we will see HPC systems with millions of cores. The real problems with this extremely large number of cores are that:
-
Memory bandwidth can’t cope with the processor speed, and
-
Programming of millions of cores is becoming a nightmare.
Next >> Many and Multicore Continued
Miha: David Ungar from IBM, who is leading the research into “many-core” processors programming, proposed to do away with node synchronizations and determinism. He abolishes “our cherished assumption that we write programs that always get the exactly right answers.” Will this be applicable in HPC?
Horst: The title of your reference, Many Core processors: Everything You know (about Parallel Programming) Is Wrong!, is revealing. A few comments:
If you have an application that is running only on 100 cores with an acceptable performance and to run it on > 100 cores doesn’t bring any performance improvements, than I would say: the app is limited to 100 cores and there is nothing wrong with it.
Programming without any synchronization is counter-intuitive, not only from a mathematical point of view. If two cores are solving one problem in 99 percent of all cases there will be some synchronization between the two cores. Otherwise, the two are solving different problems that have nothing in common.
For example: If you and I are doing a search operation in the Web, then our requests have nothing to do with each other; no synchronization required.
But if any app has to search a tree and the search will be split onto two cores, with each core responsible for different branches of the tree, then at the end both cores have to synchronize to show me the result.
Miha: What about the ant colony optimization algorithm (ACO), and other algorithms which will be thriving in many-core processors? Project Renaissance, which is sponsored by IBM Research, Portland State University, and Vrije Universiteit Brussel, deals with this topic.
Horst: Many-core systems are not only suitable for ant algorithms. This seems to be an obvious coincidence. But many-core systems are the basis for most of the technical and scientific applications that exist; including big data algorithms.
Ant algorithms are suitable for optimization problems from combinatory, i.e., the Traveling Salesman problem. The theory behind it is heuristic optimization problems, meaning it cannot be guaranteed that there exist an optimal solution or the optimal solution cannot be found in an acceptable time.

If you look at Wikipedia, ants use the environment as a medium of communication. They exchange information indirectly by depositing pheromones, all detailing the status of their “work.” The information exchanged has a local scope, only an ant located where the pheromones were left has a notion of them. Even here the term ‘medium of communication’ is mandatory.
For me I only know one synchronization-free algorithm and that’s ‘video on demand’ because two viewers, even if they watch the same movie at the same time are totally independent of each other. And if the bandwidth for accessing the same copy of a movie twice is sufficient then I would say you don’t need any communication between the two viewers – on a system level.
Next >> Big Data and Many-Core
Miha: What about big data and many-core processors?
Horst: Multicore processors and GPUs have turned almost any computer into a heterogeneous parallel machine pushing compute clusters and clouds. It is not a secret that general multicore systems are often overloaded with big data analytics. One alternative would be data centrism, meaning the memory is in the center and the CPUs are at the periphery, thus avoiding data transfer. The realization of this alternative is not easy but 2020 seems to be a reasonable deadline.
Miha: IDC predicts in 2013 “HPC architectures will begin a long-term shift away from compute centrism.” Do you agree?
Hans: The long-term shift of HPC architectures away from compute centrism seems to be a must. Today, one has the CPUs/cores in the center and the memory at the periphery. This means one always has to transfer data to the center to do the calculation. But the data transfer is limited: the memory bottleneck. The existing HPC systems can only transfer less than one byte per floating point operation.
Miha: Have you heard of Bosco? We made this tool to make scientists more comfortable using clusters. Everyone prefers a Mac to working with a cluster. Do you see a need for it in HPC?
Hans: What we at ISC have heard from Bosco is really great and we will see how it will spread over the HPC community. It really seems to make life easier for researchers to submit their jobs to remote clusters. We will think of having a session about this topic at the ISC’14. We are absolutely sure that there is a need for such a tool in the HPC environment.
Miha: High throughput computing (HTC) recently made headlines as it contributed to Higgs particle big data research at CERN. Many think HTC and HPC are converging. How do you see it happening?
Hans: The problem is the word ‘converging.’ In the future there will be a lot of HPC applications (as it is today), where numerically intensive calculations are executed on a vast amount of data; i.e., a combustion calculation in an engine.
HTC calculations will operate on extremely large datasets but are executing, in general, only a few numerical calculations on them, i.e., take the search engines and the big data research at CERN for the Higgs particle.
Now the coupling – not the converging – between HTC and HPC is coming. In the future HTC and HPC will have a strong coupling for big science. You should attend ISC’13, where we have established a session exactly for these topics.
Miha: Have you seen the University of California San Diego (UCSD) press release where researchers used Bosco to link the HPC Gordon Supercomputer to the Open Science Grid (OSG), an HTC resource? The results improved in a spectacular manner.
Hans: I would love to cover this topic at ISC Big Data’13 conference in Heidelberg, September 25-26, 2013. Sverre Jarp from CERN is the conference chair. We have just begun preparing for this event.
Fascinating Leipzig
Miha: Regarding ISC’s venue this year, why Leipzig? It seems a town that inspires and supercomputing people are incurable dreamers.
 |
|
Steven Black 2004.02, oil on canvas, 2004, 39’37” x 59’06” – courtesy Galerie Saheb New York Academy of Art – http://nyaa.edu/nyaa/exhibitions/past/leipzig.html |
Hans: Spiegel Magazine says Leipzig is the new Berlin:
Berlin used to be Germany’s hippest city, but the once scruffy capital has long since succumbed to gentrification. The latest city to attract the creative class is the former East German industrial seat of Leipzig. Moving in by the thousands, they are lured by the euphoric buzz of cheap rent and youthful ingenuity.
Before the sun sets, it pierces the clouds once again as a glowing red orb. People stream from turn-of-the-century villas and communist-era concrete apartment complexes and rush to the park. Adventurers and hedonists, painters, students, punks and Internet entrepreneurs come alone and in groups, on bicycles and skateboards, with guitars and cases of beer tucked under their arms.”
 |
|
Leipzig International Art Program – http://www.liap.eu/en/content/view/1/23/ |
In November 2012, The Green Globe designated the Congress Center Leipzig as the Best Congress and Convention Center in Europe. The ceremony took place at the Business Destinations Travel Awards 2012 in London. Watch the amazing slideshow to see why.
The ISC’13 website also has more information on the City of Leipzig.
 |
|
Quintessential Leipzig 2013 |


























































